道与术皆不远人
——漫谈人工智能技术(三)
作为《AI技术漫谈系列》的第3篇,本文我们来谈一下当前AI技术的“能与不能”。我们常说要“知人善任”,即要客观了解一个人的“能与不能”,对待技术也是这样。尤其是对于AI技术来说,客观认识其能力边界、避免无限夸大AI技术的能力甚至“威胁”,对于用好AI技术、确保AI技术健康发展都有重要的意义。
因为篇幅的原因,原定纳入本篇的内容——《电子智能与生物智能的融合——漫谈AI技术的未来》一节将单独作为本系列的第4篇文章,感谢关注。
引子,AI法师“贤二”
坐落在风景优美的海淀后山地区的北京龙泉寺,以拥有为数众多的高学历僧团而著称。高学历法师们秉持“佛法是古老的,而佛教徒是现代的”的理念,为佛法修行与传播带来了与时俱进的新气象。这不,法师们使用人工智能机器学习算法开发了一位智能机器僧——贤二法师,“他”可以用佛法与人们聊天,被称为佛教界的“Siri”(注:Siri为苹果公司开发的智能语音助手)。

居士:法师,我很烦恼。
贤二法师:烦恼既菩提。
居士:请法师明示。
贤二法师:菩提性既是佛性。烦恼暗宅中,常须生慧日。
居士:法师,我想赚很多钱,也很努力,可就是得不到,所以才烦恼。
贤二法师:佛法云,诸苦所因,贪欲为本。居士当知:世间恒如梦,犹如虚空花。空花世界,实无所得。以无所得故,无有恐怖,远离颠倒梦想,究竟涅槃。
居士:法师你说的很好,可看着身边的人赚大钱,买房买车,我心难安啊!
贤二法师:把心拿来,我为你安。
居士:这...这...这,找不着“心”呀?
贤二法师:我已经为你安完了。
上面是我们模拟的一段对话,大家不必当真。AI法师“贤二”实际上用的是人工智能机器学习算法的语言建模、文本生成功能,这与“AI写唐诗”是一个道理。下面这四首《江上田家》,只有一首是真正的唐朝诗人所作,其他都是AI诗人的作品,读起来是不是也都有模有样?各位看看能不能分清哪一首是真人所写 。

随着计算机硬件和以人工神经网络为核心的深度学习算法的突破,AI技术在许多领域都给人们带来了惊喜。接下来我们就来看一下,当前AI技术的“能与不能”。
AI技术能做什么
1. 图像识别
图像识别被认为是机器学习技术已经完全解决了的问题,也是目前AI技术应用最多、最有代表性的场景,比如无处不在的“刷脸”应用。
从技术上看 ,尽管卷积神经网络(CNN)被认为是解决图像识别问题的不二之选,但事实上,经典机器学习算法如“支持向量机(SVM)”等在一些简单的图像识别领域仍然有着良好的表现,如手写数字

然后,我们再看文本分类。
文本分类是这样一种任务,比如在互联网应用中,让程序自动识别用户的评价类型,也就是好话还是坏话。
举个例子:
“这是我用过的最好的加湿器,物美价廉,非常愉快的一次购物。”
“这个电视很差,用了两天就坏了,辣鸡。”
最初,人们是用专家系统的思路来解决文本分类问题(现在也还有),其方式是建立一个词袋,比如:好评=[好物美价廉棒满意不错愉快赞](只是示例,实际情况要更复杂),然后用这个预定义的规则去计算在用户评论中出现的次数即可,这是一种很直观的方式,适用于用户的评论用词比较标准的情况。
但实际情况中用户评论往往是很随意的,有些话不容易分清好坏,比如:
“亲,这个豆浆机的声音就像拖拉机一样好听,我也是醉了。”
“这家的洗衣机很神奇,不但能洗衣服,还会走路。”
像这类评论就很难用一个词袋来套,最好的办法是将足够多的评论数据交给机器学习算法,训练时只要告诉它每条评论的标签即可(好评或差评),让算法自己去寻找映射规则。这种情况下,当然是训练数据越多、越有代表性,训练出的模型性能就越好。
单就文本分类任务来说,多数情况下,使用循环神经网络(RNN)和使用卷积神经网络(CNN)的效果区别并不大。经典的《IMDB电影评论情感分析》案例就是一个文本分类任务。
当前的AI技术,不能做什么
面对人工智能技术,人类从来不缺乏忧患意识。早在2000年开始,一大波担心人工智能会取代人类的科幻电影就一次次地吸引了人们的眼球。不过,只要真正了解这一轮人工智能技术的底层(也可以说是当前计算机系统的底层),就会发现,这种担心就好比一对新婚夫妇担心自己未来的孙子能否考上大学一样,真的是“尚早”。
以基于高低电平(1和0)的逻辑运算为核心的计算机系统,自诞生到现在已经有七八十年的时间。在计算机的帮助下,人类社会发生了翻天覆地的变化,这段历史也被称为信息技术革命。背后的一个事实是,PC互联网也好,移动互联网也罢,包括现在不绝于耳的大数据与人工智能,这些都是在硬件之上的应用层面、也就是“玩法”层面的推陈出新。正如人类的基础科学一样,计算机原理在过去几十年时间内没有任何实质性的突破。因此可以说,这一波人工智能技术的能力边界其实早就画好了。
在这种情况下,担心人类会被AI智能机器威胁,倒不如担心类似《人猿崛起》、《生化危机》中托人类的福而突然进化加速的动物或某些病毒。
1.神经网络本质上依旧是数学框架
被冠上“人工神经网络”之名的深度学习技术近年来吸引了无数眼球,人们总是有意无意地将它和生物大脑的神经网络建立关联,甚至给人这样一种感觉:似乎AI技术已经能模拟生物的大脑了。
事实是,这只是一个“美丽的误解”。人工智能技术中的神经网络,仅仅是参考了生物大脑神经元前后相连、传递信号的这一特点而已。人工神经网络技术中的神经元,其实是一个简单的复合函数(一个线性拟合函数与一个非线性激活函数的复合),如下图:
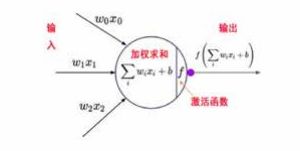
所谓AI“自主学习”,其实就是算法自动寻找输入数据与输出标签之间的映射关系,即寻找上图公式中的参数w和b。这就是当前高大上的神经网络技术的基本单元——所谓的“神经元”——你总不会担心由这样的“神经元”构成的AI产品(哪怕做成人的样子)会威胁已经在地球上生存了数百万年的、号称“万物灵长”的人类吧?
建立在1946年就发明了的“古老的”计算机系统上的这一波人工智能技术,本质上依旧是个数学求参问题,跟生物大脑没有一毛钱的直接关系。
2.反向传播(BP算法)是个巧妙的笨办法。
反向传播算法(BP算法,BackPropagation)是现代神经网络的核心机制。即:在神经网络中,数据正向传播、误差修正信号反向传播。通过误差函数(也叫损失函数,loss)来计算出当前网络的
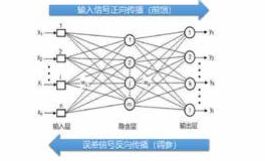
上述过程与“暴力猜密码”并无本质区别。这种学习过程是一个依靠计算机硬件能力“暴力求参”的笨办法,与人类认知世界的能力有着维度上的差距。
3. “电子机械+算法”的AI,不可能产生真正的感情
说到感情,似乎偏离了技术。实际上,量子理论研究到意识层面上,触碰的是同一个天花板,正是这个天花板让人类近百年来在基础科学上毫无进展。这涉及到“唯物”与“唯心”的古老命题——要知道,历史上“科学”正是打着“唯物”与“客观”的大旗将“唯心”与“主观”的神学推翻在地的,现在科学家们却突然发现:观察者的意识竟能决定物质在量子级别上的观察结果,这不无异于在说“世界唯心造”吗?这让千百年来科学“客观”的老脸往哪放?难怪爱因斯坦极为厌恶普朗克的不确定性原理,幸好普罗大众观测不到构成我们“坚实”的世界的微观量子世界。
AI产品要产生感情(注意不是“识别”感情),这至少是下一个时代,即电子智能与生物智能融合时代要突破的东西,那是两大技术领域融合的边缘学科,但目前人类的生物技术还看不到有任何突破的迹象。
没有感情的AI,永远只是人类的工具。
不过话又说回来,未来AI若真产生了感情,又会带来细思极恐的伦理、甚至宗教问题。一味物质化、向外求索的现代人类显然还没有准备好,再者,物质社会也不希望大家都去探求心灵问题,不然我们的GDP怎么办?
本文我们主要讨论这一波AI技术的能力边界,尽管有那么多“不能”,但AI技术已经给各行各业带来了巨大的变化,并且这一切才刚刚开始。“智者见于未萌,愚者暗于成事”,人工智能被认为是新一轮工业革命的核心,且不管它的能与不能,就算只考虑它能给我们的薪资带来的变化,也足以让人积极学习和关注了。
预告一下,本系列的下一篇文章将是名副其实的漫(八)谈(卦),因为谈的都是未来可能的事儿。与眼下的AI赋能相比,电子智能与生物智能融合的时代真的尚远。但正如比尔·盖茨预言的那样:“二十一世纪是生物技术的世纪,下一个世界首富很可能出自这个领域。”

识别、车牌号与银行卡的识别等。
一般来说,相对于经典机器学习,神经网络的表现能力更强,适合用来映射更复杂的规则、处理更复杂的数据,当然硬件性能也要跟上。
另外,图像比对(即判断两张图片的相似度)以及物体检测(目标检测)也通常被看做是广义的图像识别类任务。
图像识别类任务除了涉及到神经网络技术之外,还常会用到以OpenCV为代表的计算机视觉处理技术。另外,一些不错的专用机器学习框架如YoLo3(目标检测)、OpenPose(人体姿态识别)等也比较常用。


2. 语音识别
语音识别和图像识别都属于感知类的任务,这一类任务的解决方案已经比较成熟。除了语音控制、语音助手外,我们这两年接到的骚扰电话也有许多是AI代劳的。
苹果公司大名鼎鼎的智能语音助手Siri,甚至成了大伙的消遣娱乐对象。
语音识别的关键技术是语言建模,也就是建立能够涵盖特定语言要素的语言模型。
从技术上看,语音识别处理的数据通常是时序数据,即数据是有时间先后顺序的。与卷积神经网络齐名的另一种神经网络— — 循环神经网络(RNN)被专门设计用来处理这类数据,它通过类似物理电路中的多种“功能门”结构实现了“记忆”功能,因此更适合处理带有上下文关系的数据。一个经典的提法是,都是进行特征提取,但卷积神经网络是在空间上拓展,而循环神经网络是在时间上拓展。
另外,像多语言互译这类应用目前也比较成熟,这也是语音识别技术的典型应用。
3. 自然语言处理(NLP)
机器学习中,涉及到自然语言数据的任务被独立看做一个大类(注意和语音识别有重叠之处)。除了前面提到的文本生成外,常见的NLP任务还有文本分类。
先看文本生成。
以写诗机器人为例。比如,我们想训练一个会写豪放派古诗的AI机器人(也可以是会写莎士比亚诗的“AI莎翁”),我们怎么做的呢?首先,把辛弃疾、李白、苏轼等等能找到的豪放风格的诗都准备好,越多越好,这是数据(也叫语料),数据的标签就是“豪放派”,在机器学习中,标签我们一般用数字来表示。因为交给算法学习的数据是带标签的 ,所以这是“监督学习 ”( S u p e r v i s e d Learning)。接下来,机器学习算法会将处理好的语料(基本单元可以是字、也可以是词、甚至是句子)与标签(“豪放派”)建立映射关系(即对应关系),这个过程就是模型的训练。训练的结果是符合 准确率 要求的映射 规则(即神经网 络的参数),这类似于寻找一个复合函数的参数,也就是上一篇我们讲的,神经网络实际上是将特征识别问题转化成了数学映射问题(求参数问题)。
